
 Opublikowano 1. marca 2018r.
Opublikowano 1. marca 2018r. 

W ostatnim czasie miałem niezwykłą przyjemność uczestniczyć w cyklu wykładów, które kosztowały więcej niż moja pensja netto (koszty pokrył pracodawca, no bo jak inaczej…). Jeden z wykładów poświęcony był popularnemu ostatnio pojęciu machine learning czyli uczenie maszynowe zastosowane w praktyce.
Pokrótce, pomysł uczenia maszynowego pojawił się już w połowie ubiegłego wieku, ale dopiero ze względu na rozwój informatyki w ostatnich kilkunastu latach i ogromnej mocy obliczeniowej komputerów, stało się możliwe zastosowanie tej metody w wielu dziedzinach, gdzie potrzebni są wirtualni pomocnicy. W internecie jest sporo artykułów o tym, na czym uczenie maszynowe polega, ale najtrafniej przedstawia to artykuł w CD Action 11/2017 z łatwym przykładem do zrozumienia – analiza zdjęć.
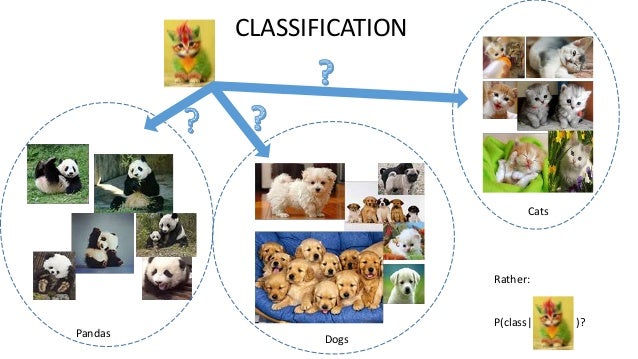
Załóżmy, że chcemy, aby pokazywać programu komputerowemu dowolne zdjęcie, a on ma stwierdzić, czy na tym zdjęciu jest kot. Główną ideą uczenia maszynowego jest to, że nie powiesz (albo bardzo mało) komputerowi, jak wygląda kot – on sam ma do tego dojść. Możesz zatem powiedzieć „to takie stworzenie, które ma cztery łapy, futerko i lubi spać”, definicja ogólna, ale jak najbardziej ok. Jeśli jednak poprosisz komputer, by na podstawie tej definicji narysował to zwierzę, zapewne narysuje coś, co w ogóle kota nie przypomina. Wtedy my mówimy, że to nie jest kot, ale proszę, tutaj 1000 zdjęć z kotami, pooglądaj je i spróbuj zrozumieć swój błąd.
Ćwiczenie – jeśli uważacie, że przykład jest bez sensu,
| Spojler | Pokaż |
|---|---|
Gdy komputer „zczai” już jak wygląda kot, kontynuujemy etap nauczania, bombardując go milionami zdjęć, różnych, zawierających koty oraz bez nich, z pytaniem „czy na tym zdjęciu jest kot?”. Komputer „zgaduje” na podstawie swoich wcześniejszych doświadczeń tak/nie, a następnie sprawdza z człowiekiem, czy udzielił poprawnej odpowiedzi, podnosząc cały czas swoją wiedzę. Oznacza to, że wraz z kolejnymi przykładami będzie rosła skuteczność rozpoznawania obrazów, aż osiągnie on poziom wyższy, niż ma człowiek (90 kilka procent)!
W ten sposób otrzymaliśmy program komputerowy, który jest wydajniejszy i szybszy od człowieka. Pomyślcie tym samym, ile możliwych różnych zastosowań może mieć nauczanie maszynowe… Odpowiednio nauczone maszyny mogą odkrywać relacje, rozwiązywać zawiłe problemy czy optymalizować procesy, o ile dostaną ogromną porcję wiarygodnych danych… I będą to robić lepiej niż jakikolwiek człowiek.

Przejdźmy zatem do clou notki. Wykład polegał na pokazaniu zastosowaniu nauczania maszynowego w ubezpieczeniach, a konkretny problem skupiał się na wycenie polisy OC. Kalkulacja takiego OC obarczana jest nomen-omen pewnym ryzykiem, bowiem nie da się w momencie zawarcia polisy stwierdzić:
1. Czy oraz ile szkód nastąpi w trakcie trwania polisy?
2. Jaka będzie sumaryczna wartość szkód?
3. Kiedy nastąpi zgłoszenie szkody (zgłoszenie może pojawić się nawet kilka lat po zakończeniu polisy, ale szkoda nastąpiła w momencie trwania polisy!)?
Towarzystwo ubezpieczeniowe, by ustalić wysokość OC, korzysta z wielu czynników, które na etapie modelowania statystycznego dają najwięcej odpowiedzi na postawione powyżej pytania. Część jest oczywista, jak np. marka auta, model auta, wiek kierowcy, miejsce zamieszkania kierowcy, staż kierowcy, wiek współwłaściciela, staż współwłaściciela, bezszkodowa jazda. Inna część już nie do końca np. kolor samochodu, wielkość tłumika, obecność CB radia, stopień przyciemnienia szyb, średnia wieku samochodów w okolicy miejsca zamieszkania.
Pytanie – jak myślicie, ile zmiennych może być używanych do wyliczenia składki?
| Spojler | Pokaż |
|---|---|
Całkiem sporo, co nie? Problemem jest więc spiąć to wszystko razem. Ci z was, którzy mieli statystykę na poziomie wyższym niż średnia czy mediana, usłyszeli o rozkładzie Poisson czy o modelach liniowych i tak, to co mówi się na wykładach, że są one wykorzystywane do wyliczenia OC, to prawda. A przynajmniej były używane.
| Spojler | Pokaż |
|---|---|
Prezentujący powiedział, że w jego firmie ubezpieczeniowej postanowiono przetestować możliwość wprowadzenia uczenia maszynowego do wyliczenia składek. Możecie więc sobie wyobrazić, że odpowiedni program komputerowy był bombardowany milionami danych, by sam oszacował wielkość możliwej szkody, a następnie porównał z rzeczywistą szkodą. Efekt możecie przewidzieć – przeszkolony program komputerowy wyliczał prawdopodobieństwo szkody lepiej, aniżeli matematyczny model i w ten sposób dobierał wysokość polisy bardziej adekwatnie.

Tak w przybliżeniu możemy wyobrazić sobie sposób, w jaki komputer modeluje.
Wszystko fajnie, jest jednak jedno wielkie, ale to wielkie ALE. O ile model matematyczny można zrozumieć i uzasadnić, tak model dobrany przez komputer jest niewytłumaczalny, nawet dla twórców aplikacji. Oznacza to więc, że popularne stwierdzenie „bo komputer tak wyliczył” (zapraszam po więcej Maszyna myśli, człowiek nie), które kiedyś było używane w kontekście zwyczajnej niewiedzy albo lenistwa, by zrozumieć, tak dzisiaj będzie używane coraz częściej, bowiem naprawdę nikt nie będzie w stanie wyniku komputera zinterpretować i wybronić. Możemy w ten sposób dojść do abstrakcyjnej sytuacji, że komputer wypluje wynik kompletnie bez sensu, ale będziemy uznawać wyższość maszyny, bo przecież się nie myli.
Czytając co nieco o nauczaniu maszynowym, nasuwa się pytanie – czyżby SkyNet był coraz bliżej? Naukowcy twierdzą, że nie, w końcu maszyny uczą się, by pomagać człowiekowi i wyręczać z (monotonnych) zadań, chociaż grupa niezgadzająca się z tą tezą będzie rosła tak szybko, jak szybko uczenie maszynowe będzie odgrywać coraz większa rolę w naszym życiu.



